Basics on memory API, segmentation & free space management
- There is the physical memory and the address space which is an abstraction on top of the physical memory.
- each segment has 4 types of memory: Heap, stack, code and data.
- The Data Segment is technically split into two distinct parts:
- Initialized Data Segment (
.data): This holds global and static variables that you explicitly initialized with a specific value in your code. Example*:*int global_count = 100; - Uninitialized Data Segment (
.bss): This holds global and static variables that are either uninitialized or initialized to zero. The OS automatically fills this memory with zeros when the program loads. (BSS historically stands for “Block Started by Symbol”). Example*:*int global_count;orint global_count = 0;
- Initialized Data Segment (
- stack is implicitly managed for you by the compiler while heap is managed by the programmer (you).
void func() {
int *x = (int *) malloc(sizeof(int));
...
}- given this program,
mallocwill allocated the memory on the heap andint *xis a pointer that will point to the allocated memory region. This pointer is saved on the stack. - You can provide how much memory you need in malloc() but instead of providing a number use
sizeof(___)where you can put anything like double, int32, int64, etc. free()will help you to free the memory which is allocated by malloc.- In other languages, you dont need to call
freesince there is an automatic garbage collector that runs, figures out what you dont need and automatically dereferences it for you. - segmentation fault: error when program tries to access region of memory which is not allocated yet / is not supposed to access.
- buffer overflow: error when you didn’t allocated enough memory
- uninitialized read: you allocated memory to the heap but you didnt initialize it with some data, so it will read some data of unknown value.
- memory leak: you didnt free the memory and you eventually run out.
- dangling pointer: when the program frees the memory before it finishes using it, there is a chance that valid memory is overwritten.
- double free: programs free memory more than once, result is undefined.
- address translation is when the hardware turns the virtual address into a physical address.
- OS needs to get involved at points so that correct translations can take place, ie it must manage memory, keeping track of which locations are free and which are in use. The goal is to show that the program has its own private memory when in reality there are many programs which are actually sharing memory at same time.
- dynamic relocation: a base register and a bounds (or limit) register is used every time a program generates a memory reference (a virtual address), the hardware translates it on the fly.
Physical Address = Virtual Address + Base- Before accessing the physical memory, the hardware checks if the virtual address is legal. If the virtual address is greater than or equal to the bounds register, or if it is negative, the CPU raises an exception.
- This guarantees that a process can only access its own sandbox of memory
- static relocation: loader takes an executable that is about to be run and rewrites its addresses to the desired offset in physical memory. However, it doesnt provide protection as processes can generate bad addresses and thus illegally access other process’s or even OS memory.
- In base and bounds there will alot of free space in the middle between stack and heap.
- Segmentation solves this by having one pair of base and bounds per logical segment of address space instead of one pair per memory management unit (MMU).
- In a 14 bit virtual address, the first 2 bits tell the hardware which segment (code, stack, heap) to refer to and remaining 12 bits are offset into the segment.
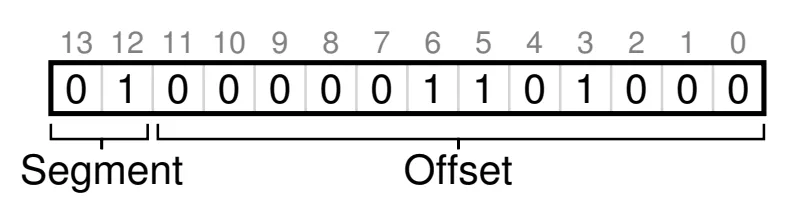
-
sometimes the heap and code are represented in the same segment so they only use 1 bit. This is explicit approach
-
In the implicit approach the hardware determines which segment by looking at how the address was formed (program counter means its code segment, stack/base pointer means it is stack segment anything else is heap segment).
-
we also need the direction of growth, if a bit in the segment is set to 1 then it grows in positive direction, else negative direction.
-
to save memory it is common to share memory as well. This is done through protection bits, where a few bits are added per segment indicating whether a program can read/write into segment.
-
coarse grained segmentation: few segments
-
fine grained segmentation: there are alot of smaller segments
-
one problem is that physical memory becomes full of small holes of free space to allocate new segments, this problem is called external fragmentation.
-
one solution is compaction which rearranges all the segmnets to be together but it is an expensive operation. It also makes it harder for existing segments to grow in size.
-
Below are some notes on how to calculate base and bounds registers and address translations (excuse my bad handwriting):

-
internal fragmentation is when more memory is allocated in the block than is actually needed, leaving a lot of unused space inside the block.
-
a free list contains a set of elements that describe the free space remaining in the heap
-
2 operations for free list: splitting and coalescing
- Splitting: When the allocator finds a free block that is larger than the requested size, it doesn’t want to waste the leftover space. Instead, it carves the block into two pieces.
- Piece 1: The exact size requested by the user (marked as allocated).
- Piece 2: The remaining chunk, which is put back into the free list for future use.
- Coalescing happens during memory deallocation (free call). When a block of memory is freed, the allocator looks at its immediate neighbors in physical memory. If the neighboring blocks (left or right) are also free, the allocator merges them into one single, larger continuous block. Without it, you will suffer from external fragmentation.
- Splitting: When the allocator finds a free block that is larger than the requested size, it doesn’t want to waste the leftover space. Instead, it carves the block into two pieces.
-
most allocators keep track of the size of allocated memory through header block in memory
-
magic number is also kept track of for integrity checking
typedef struct {
int size;
int magic;
} header_t; - the free space list needs to be built inside the free space itself
- techniques to determine which free space block to choose:
- Best Fit & Worst Fit
- Search Method: Requires an exhaustive search of the free space list.
- Best Fit Side Effect: Has a tendency to “splinter” the first free space node, leaving many tiny free spaces inside the node.
- First Best Fit
- Why they do it: Scans the list from the beginning and selects the first free block that is big enough. It is much faster than an exhaustive search.
- Disadvantages: Pollutes the beginning of the free list with small, fragmented blocks, forcing later allocations to scan further down the list.
- Next Best Fit
- Why they do it: Leaves a pointer on the previously allocated node and begins the next search from that exact location, distributing allocations more evenly across the memory.
- Disadvantages: Can result in worse overall fragmentation because it blindly skips over valid, smaller free blocks at the beginning of the list.
- Buddy Allocation System
- Why they do it: Divides memory into power-of-two sizes (2^n). When memory is freed, it is incredibly easy to find its adjacent “buddy” and coalesce them back together.
- Disadvantages: Suffers from severe internal fragmentation. If you request 65 KB, it must round up and allocate a full 128 KB block, wasting nearly half of it.
- Segregation Lists
- Why they do it: Maintains 2 (or more) different lists—typically a main one for common sizes and a less frequently used one for others. This speeds up allocation by categorizing free blocks by size.
- Disadvantages: Adds architectural complexity and can lead to memory trapping (one size-list runs out of memory and starves, even though another size-list has plenty of free space).
Everything on Paging
-
dividing address space into different size chunks leads to fragmentation
-
paging allows for division into fixed size pieces called page.
-
physical memory is viewed as a array of fixed size slots called page frames.
-
page table stores address translations from virtual pages to where each page resides in physical memory.
-
to translate the virtual address, it must be split into virtual page number (VPN) and offset within page (which byte we want within page). VPN is converted into physical frame number while offset stays the same.
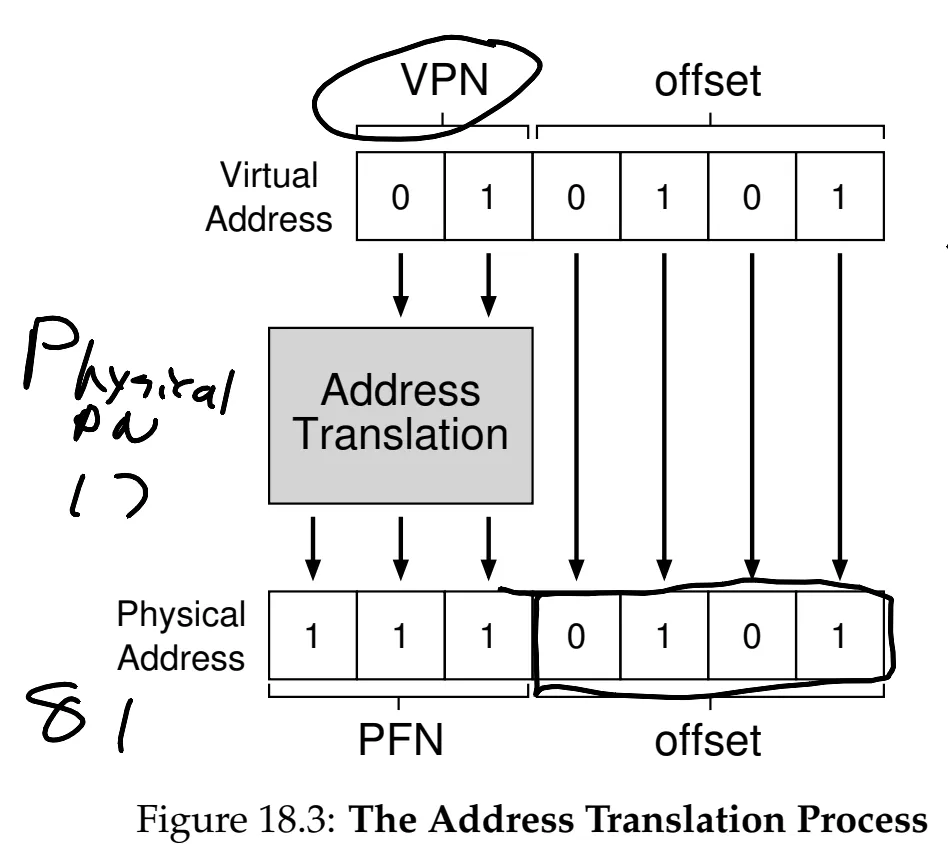
-
for a page table entry (PTE), we have a number of different bits in there.
- A valid bit indicates whether a translation is valid, all unused space between code+heap and stack will be marked as invalid
- protection bits indicate whether a page can be read from, written to, or executed from
- present bit indicates whether page is in physical memory or on disk
- dirty bit indicates whether the page has been modified since it was brought into memory
- reference bit is used to track whether a page has been accessed or not (whether it should be kept in memory or swapped to disk)
-
page table is maintained per process, pages themselves arent.
-
paging requires a large amount of mapping and this info is generally stored in physical memory. This means that paging requires an extra memory lookup for each virtual address generated by the program.
-
To speedup address translation, a translation lookaside buffer (TLB) is used. TLB is part of the chip’s MMU and is a hardware cache of popular virtual to physical address translations.
-
TLB algorithm:
- The CPU checks the TLB using the VPN to see if the translation is already cached.
- TLB Hit (Fast Path):
- If the VPN is found, it is a TLB Hit.
- The hardware immediately retrieves the matching Physical Frame Number (PFN).
- The PFN is combined with the original offset to form the final physical address, and memory is accessed directly.
- TLB Miss (Slow Path):
- If the VPN is not found, it is a TLB Miss.
- The hardware or operating system must perform a page table walk, looking up the translation in the main memory’s page table (which takes much longer).
- Once found, the new translation is loaded into the TLB so it can be used for future requests.
- TLB Eviction: If the TLB is full when a new translation is loaded, an existing entry must be kicked out (evicted), typically using a policy like Least Recently Used (LRU).
-
Spatial locality is the principle that if a program accesses a specific memory location, it is highly likely to access nearby memory locations in the near future. Due to spatial locality, when a program moves from one variable to the next adjacent variable, those variables almost always reside on the exact same memory page.
-
If we were to access the same elements again, it would lead to cache hit due to temporal locality (quick re-referencing of memory items in time).
-
TLB can be managed by hardware and software:
- hardware walks the page table , find correct page table entry and extract the information
- software managed TLB is where current instruction stream is paused, raise privilege level to kernel mode and jumps to a trap handler (its like system level call).
-
When switching from one process to another, the hardware/OS must ensure that about to run process does not make use of the translations from some previously run process.
- one solution is to simply flush the TLB on context switches. However if the OS switches between processes too much, the cost may be high.
- address space identifier field is another solution which is used to differentiate between identical translations.
-
cache replacement: when adding new entry into TLB, we have to replace the older one. How can we do so while minimizing the miss rate.
- LRU takes advantage of locality in memory reference stream, assuming it is likely that an entry that has not recently been used is a good candidate for eviction.
- random policy is also good choice when LRU behaves poorly, for eg when program loops over n+1 pages with a TLB of size n.
-
page tables are very big, in a 32 bit system (2^32), with 4kb (2^12) pages and a 4 byte page table entry. Then address space will have roughly (2^32 / 2^12 = 1 mil) pages. Multiply this with size of PTE and you can see page table itself is 4MB.
- one solution is bigger pages, but it can lead to internal fragmentation
- hybrid approach: Combines Segmentation and Paging to get the benefits of both worlds.
- Programs usually have a huge, unallocated gap between the heap (growing down) and the stack (growing up). The OS must still dedicate thousands of page table entries just to mark that massive empty gap as “invalid,” wasting precious memory.
- Instead of one massive page table for the whole process, the address space is split into logical chunks (Code, Heap, Stack), and each segment gets its own small page table.
- The hardware’s Memory Management Unit (MMU) now maintains Base Register which no longer points to the data itself, instead it now holds the physical address of that segment’s page table. The bounds Register tracks the number of valid pages in that segment’s page table, rather than raw byte size.
- If a code segment only uses 3 pages, its page table is exactly 3 entries long, and its bounds register is set to 3. Anything beyond that triggers an out of bounds exception.
- A virtual address is split into three parts: Segment bits (SN) at the top, Virtual Page Number (VPN) in the middle, and Offset at the end. On a cache miss, the hardware uses the SN bits to select the right base register, then calculates the exact Page Table Entry (PTE) location using this formula:
- The segment page tables can now be arbitrary sizes, finding free physical memory slots to fit them becomes difficult again. (external fragmentation). It also still relies on the predictability of segments. If a program has a “sparse” heap (allocating one piece of data at the start and another piece very far away), the page table must still grow large enough to cover the entire gap, reintroducing memory waste.
- multi level page tables
-
Instead of treating the entire page table as one giant, continuous block of memory, a multi-level page table does two things. It breaks the massive linear page table into smaller, bite-sized, page-sized chunks. If a chunk consists entirely of “invalid” entries (meaning the program isn’t using that part of memory), it isn’t allocated at all. It completely disappears from RAM.
-
It uses a new master index called the Page Directory.
-
The Page Directory is made up of Page Directory Entries (PDEs).
-
Each PDE points to one of the chopped-up pieces of page table.
-
If a PDE’s valid bit is 1, it means that there is active data here*.* If a PDE’s valid bit is 0, it means it is empty*.* The system doesn’t even bother creating that piece of the page table, saving massive amounts of space.
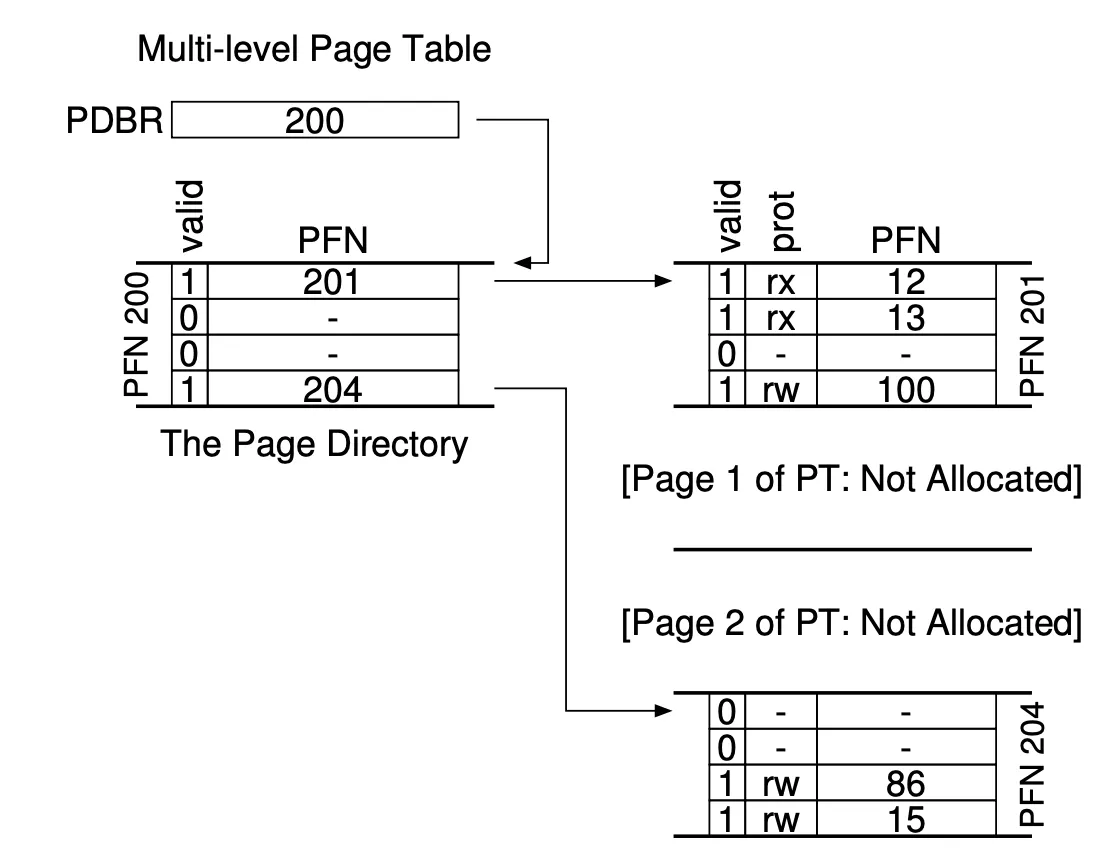
-
-
when your memory gets so big that the Page Directory itself no longer fits on a single page, you chop up the Page Directory into page-sized units, and put a Top-Level Page Directory on top of those.
-
Modern 64-bit systems have massive address spaces, which is why they routinely use 4-level or 5-level page tables to make sure every piece fits perfectly within a standard page.
-
- inverted page table: single page table that has an entry for each physical page in system. the PTE tells which process is using the page and which virtual page of the process maps to this physical page.
Swapping pages to disk
- to support large address spaces, OS needs to stash portions of address space that aren’t in demand into the disk.
- the space reserved in the disk for moving pages is called swap space.
- The size of the swap space dictates the maximum number of memory pages a system can use at any given time.
- Physical memory and swap space can be actively shared across multiple running processes, while fully swapped-out processes remain inactive on disk.
- present bit in PTE helps to identify whether the page is located in disk or in physical memory.
- Accessing a legal page that has a present bit of zero causes the hardware to raise an exception, transferring control to an OS page-fault handler. Page faults are managed in software because disk I/O operations are slow enough that software overhead is minimal, and because it keeps hardware design simple by not requiring it to understand swap space or disk I/O operations.
- During a fault, the OS finds a physical frame, reads the page from swap space into memory using a disk address stored in the PTE, and updates the PTE (marking it present and adding the PFN). While disk I/O is in flight, the faulting process enters a blocked state, allowing the OS to run other ready processes to optimize hardware use. Once I/O completes, the original instruction is retried, resulting in a TLB miss, a TLB update, and finally a successful memory access via a TLB hit.
- When physical memory is full, the OS must rely on a page-replacement policy to decide which page to evict. Making a poor replacement choice can significantly degrade program performance, forcing it to run at disk-like speeds instead of memory-like speeds.
- Instead of waiting for memory to completely fill up, modern operating systems run a proactive background thread (the swap or page daemon). It awakens when available memory drops below a low watermark (LW) and evicts pages until reaching a high watermark (HW).
- Performing replacements in the background allows the OS to cluster or group multiple pages together to write them out at once, which noticeably reduces seek and rotational overheads on hard disks
- When physical memory space is limited, memory pressure forces the OS to treat main memory as a cache for the system’s virtual memory pages, paging out less actively used blocks to make room.
- A metric used to evaluate cache policy performance, calculated using the formula, where is the memory access cost, is the disk access cost, and is the probability of a cache miss:
- Because the cost of disk access is massive compared to memory access , such as 10 milliseconds versus 100 nanoseconds, even a tiny miss rate can heavily dominate the overall AMAT, emphasizing the need for smart replacement policies.
- The Three C’s of Cache Misses:
- Compulsory Misses: Also called cold-start misses, occurring because the cache is initially empty and an item is referenced for the first time.
- Capacity Misses: Occurring when the cache runs out of space and must evict an existing item to bring in a new one.
- Conflict Misses: Arising in hardware caches due to placement limitations (set-associativity); they do not occur in OS page caches because they are fully-associative.
- Page replacement policies are as follows:
- The Optimal Replacement Policy (MIN)
- serves as an ideal comparison baseline by replacing the page that will be accessed furthest in the future, resulting in the absolute fewest possible cache misses.
- It is impossible to implement in a general-purpose operating system because the future memory reference stream is not known ahead of time.
- First in first out
- pages are arranged in a queue as they enter memory
- It performs poorly because it cannot determine page importance, frequently evicting heavily accessed pages simply because they were loaded early.
- Belady’s Anomaly: A phenomenon unique to non-stack property algorithms like FIFO where increasing physical cache size can unexpectedly cause the hit rate to get worse rather than better on specific reference streams.
- Random Replacement
- stateless policy that chooses a random page to evict under memory pressure, making it simple to implement but unintelligent.
- can outperform FIFO and LRU in specific worst-case scenarios (when a program repeatedly references a fixed set of pages in a strict, sequential sequence (for example: 0, 1, 2, …, 49, and then looping back to 0, 1, 2…). This type of memory access pattern is common in important commercial applications, such as databases)
- Historically-Based Policies (LRU & LFU)
- Based on the Principle of Locality, which dictates that programs naturally display temporal locality (pages accessed recently are likely to be accessed again soon) and spatial locality (pages physically near an accessed page are likely to be accessed next).
- Least-Frequently-Used (LFU): Evicts the page with the lowest access frequency history.
- Least-Recently-Used (LRU): Evicts the page that has not been accessed for the longest period of time.
- Opposite Variants: Includes Most-Frequently-Used (MFU) and Most-Recently-Used (MRU), which generally perform poorly because they ignore program locality.
- The Optimal Replacement Policy (MIN)
- Performance on different workloads:
- No-Locality Workload: Consists of completely random page accesses; all realistic policies (LRU, FIFO, Random) perform identically, and hit rates are determined entirely by cache size.
- 80-20 Workload: Emulates realistic locality where 80% of references target 20% of the pages (“hot” pages); LRU clearly outperforms FIFO and Random because it successfully uses history to preserve hot pages in cache.
- Looping-Sequential Workload: Loops sequentially through a fixed set of pages (e.g., 0 to 49); this represents a catastrophic worst-case scenario for both LRU and FIFO, yielding a 0% hit rate if the cache cannot hold the entire loop, while Random performs notably better.
- Perfect LRU requires costly accounting work on every single memory reference to update data structures, severely hindering system performance.
- While hardware could stamp an array of access times, scanning a massive array of millions of physical pages during every single eviction is prohibitively slow.
- To approximate LRU efficiently, hardware implements a single use bit (reference bit) per page, setting it to 1 upon any read or write access
- An approximation of LRU where pages are treated as a circular list tracked by a moving clock hand. When an eviction is needed, the OS inspects the page:
- If the use bit is 1, it clears it to 0 and advances.
- If the use bit is 0, that page is selected as the replacement victim.
- An optimization to the clock algorithm that incorporates a hardware modified bit (dirty bit). Because evicting a modified page requires an expensive disk write, the algorithm prioritizes evicting clean, unused pages before dirty ones.
- Demand Paging: The default approach where the OS loads pages into memory strictly “on demand” when they are actively accessed.
- Prefetching: Proactively loading adjacent pages (e.g., page after page ) before they are requested, based on a high probability of success.
- paging problems:
- Thrashing: Occurs when the total active working sets of running processes exceed physical memory capacity, causing the system to spend all its time constantly paging blocks to and from disk
- Admission Control: A mitigation technique where the OS stops running a subset of processes to allow the remaining ones to fit their working sets into memory and make progress.
- Out-Of-Memory (OOM) Killer: A drastic, modern approach (used in Linux) that automatically runs a daemon to select and kill a memory-intensive process to abruptly eliminate extreme memory pressure.